
I am Yuxuan Wang, currently a fourth-year Ph.D. candidate from
MReaL Lab in Nanyang Technological University (NTU) supervised by Prof.
Hanwang Zhang.
Previously, I received my Master of Science degree from the Show Lab in National University of Singapore (NUS), where I was advised by Prof.
Mike Zheng Shou.
I also collaborate closely with Prof. Long Chen from HKUST and Prof. Na Zhao from SUTD.
My research interest includes but not limited to 3D Generaton, 3D Scene Editing and Understanding, and Vision-Language Understanding.
I’m graduating in 2026 and open to employment opportunities in Singapore, Mainland China, and Hong Kong SAR. Feel free to contact me~!
Education
-
 Nanyang Technological UniversityCollege of Computing and Data Science
Nanyang Technological UniversityCollege of Computing and Data Science
Ph.D. CandidateAug. 2022 - present -
 National University of SingaporeElectrical and Computer Engineering
National University of SingaporeElectrical and Computer Engineering
Master of ScienceAug. 2021 - Jun. 2022 -
 Beihang UniversityElectronic and Information Engineering
Beihang UniversityElectronic and Information Engineering
Bachelor of EngineeringSep. 2016 - Jun. 2020
Experience
-
 Tencent, Hunyuan3D AIGC Center
Tencent, Hunyuan3D AIGC Center
Research Intern2024 -
 MReaL Lab, NTUCollege of Computing and Data Science
MReaL Lab, NTUCollege of Computing and Data Science
Research Associate2022 -
 Inspur Co., LtdInspur International
Inspur Co., LtdInspur International
Software Develop Intern2021
News
Publications
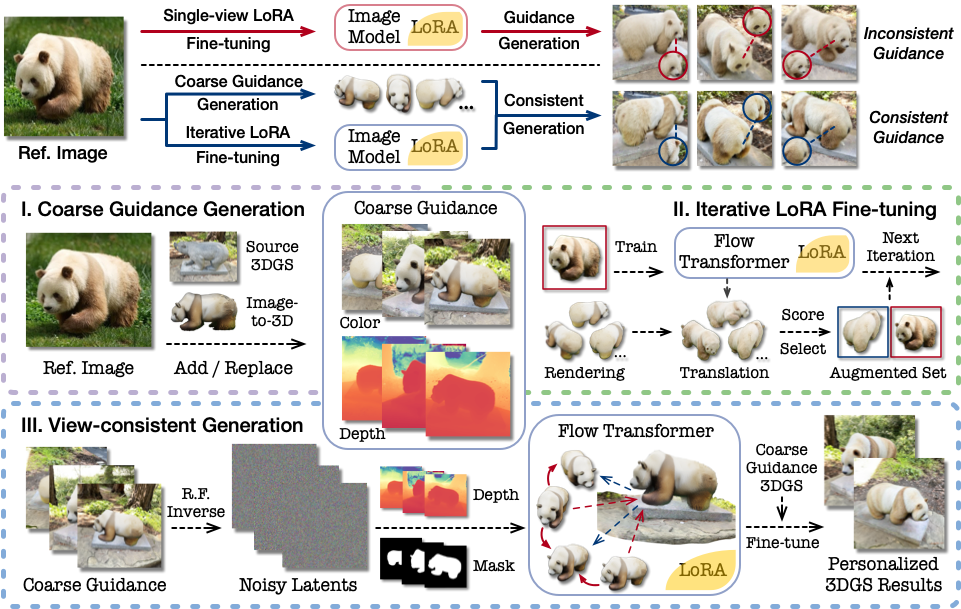
Personalize Your Gaussian: Consistent 3D Scene Personalization from a Single Image
Yuxuan Wang, Xuanyu Yi, Qingshan Xu, Yuan Zhou, Long Chen, Hanwang Zhang
AAAI Conference on Artifical Intelligence (AAAI), 2026
We present Consistent Personalization for 3D Gaussian Splatting (CP-GS), a framework that progressively propagates the single-view reference appearance to novel perspectives, offering high-quality 3DGS personalization with faithful referential alignment.
Personalize Your Gaussian: Consistent 3D Scene Personalization from a Single Image
Yuxuan Wang, Xuanyu Yi, Qingshan Xu, Yuan Zhou, Long Chen, Hanwang Zhang
AAAI Conference on Artifical Intelligence (AAAI), 2026
We present Consistent Personalization for 3D Gaussian Splatting (CP-GS), a framework that progressively propagates the single-view reference appearance to novel perspectives, offering high-quality 3DGS personalization with faithful referential alignment.
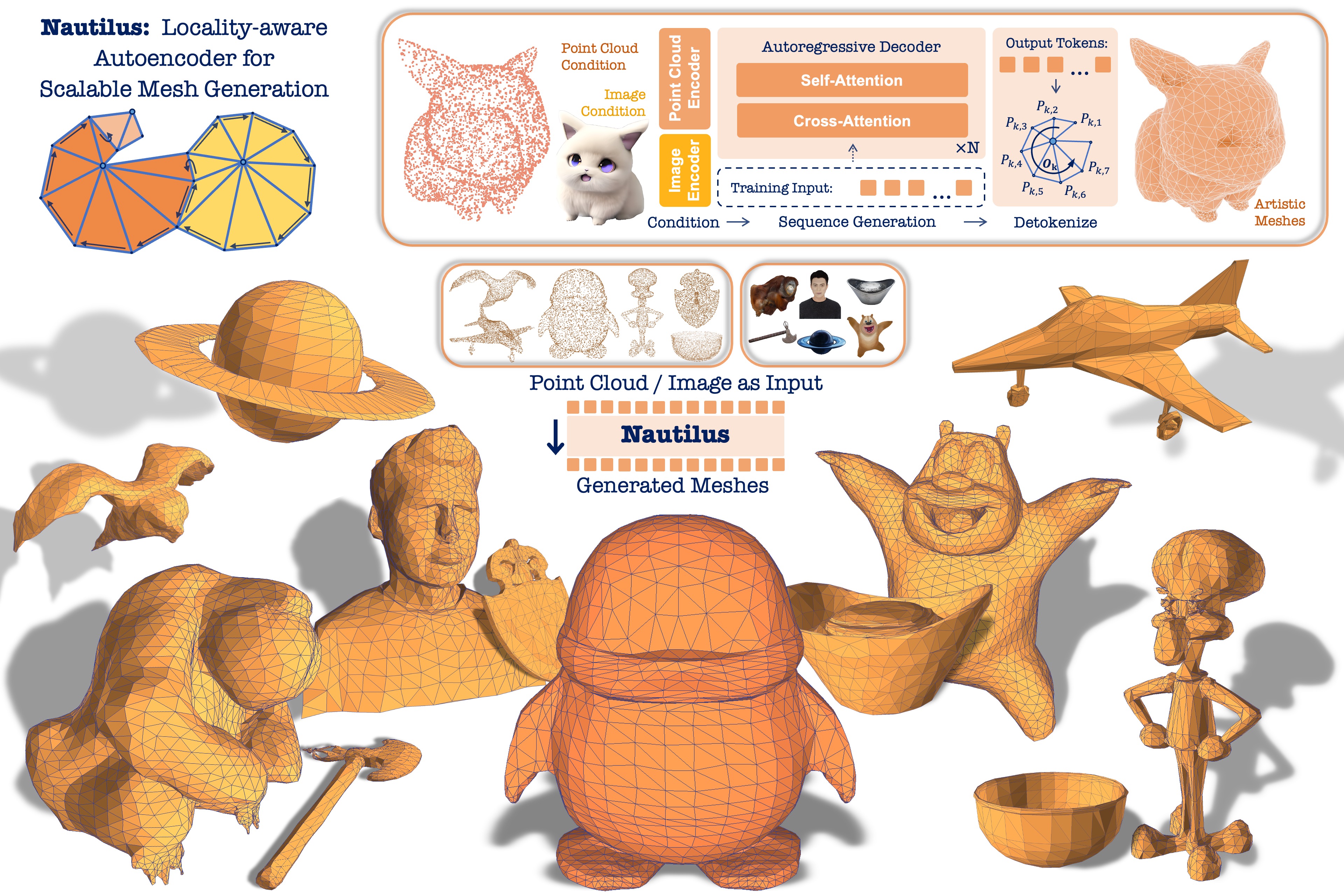
Nautilus: Locality-aware Autoencoder for Scalable Mesh Generation
Yuxuan Wang*, Xuanyu Yi*, Haohan Weng*, Qingshan Xu, Xiaokang Wei, Xianghui Yang, Chunchao Guo, Long Chen, Hanwang Zhang ( * co-first authors)
International Conference on Computer Vision (ICCV) 2025
We propose Nautilus, a locality-aware autoencoder for artist-like mesh generation, which leverages the local properties of manifold meshes to achieve structural fidelity and efficient representation.
Nautilus: Locality-aware Autoencoder for Scalable Mesh Generation
Yuxuan Wang*, Xuanyu Yi*, Haohan Weng*, Qingshan Xu, Xiaokang Wei, Xianghui Yang, Chunchao Guo, Long Chen, Hanwang Zhang ( * co-first authors)
International Conference on Computer Vision (ICCV) 2025
We propose Nautilus, a locality-aware autoencoder for artist-like mesh generation, which leverages the local properties of manifold meshes to achieve structural fidelity and efficient representation.
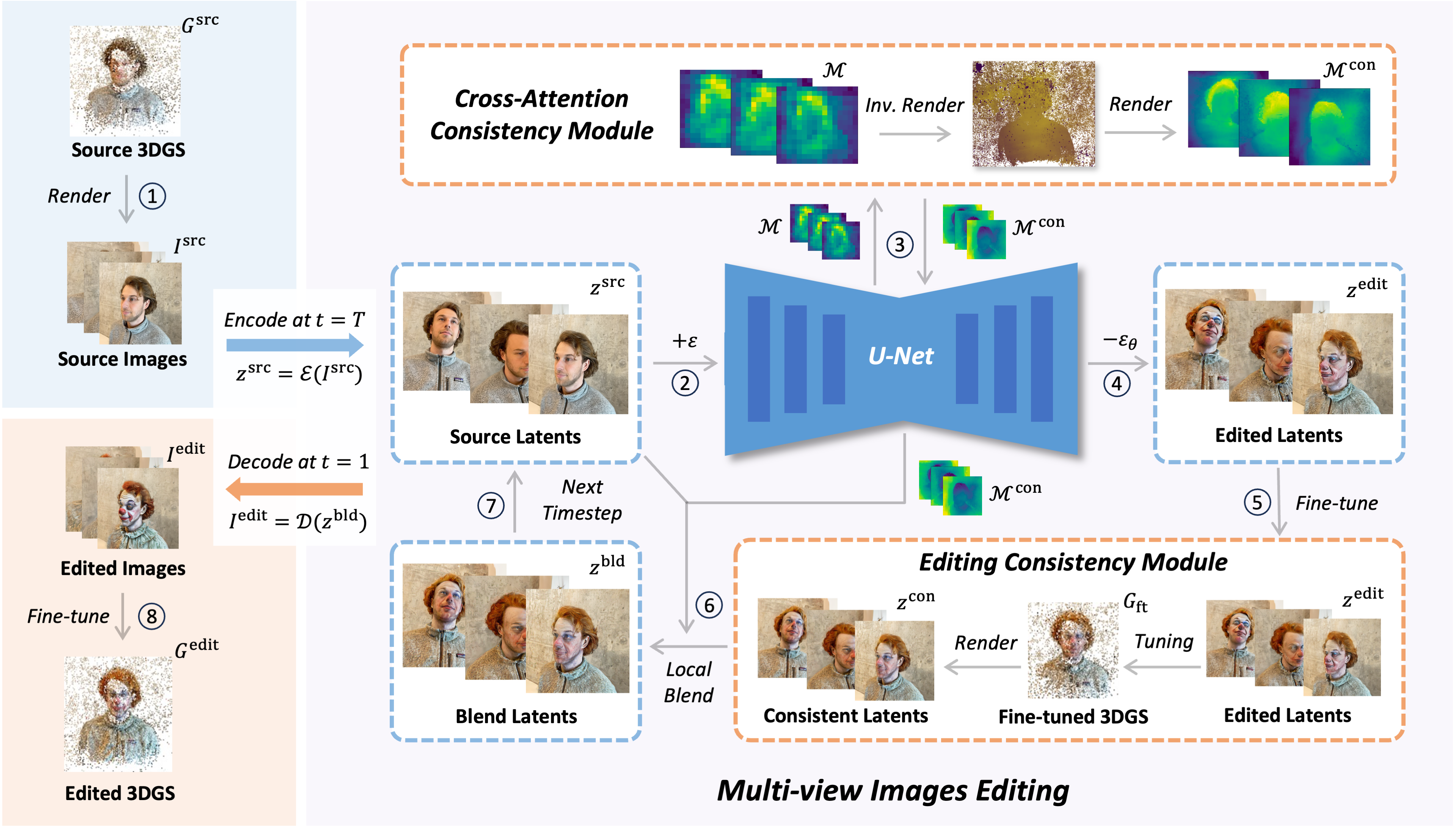
View-Consistent 3D Editing with Gaussian Splatting
Yuxuan Wang, Xuanyu Yi, Zike Wu, Na Zhao, Long Chen, Hanwang Zhang
European Conference on Computer Vision (ECCV) 2024
In the diffusion model, we proposed effective multi-view consistency designs that harmonize the inconsistent multi-view image guidance by integrating with 3D Gaussian Splatting (3DGS) characteristics, offering high-quality 3DGS editing.
View-Consistent 3D Editing with Gaussian Splatting
Yuxuan Wang, Xuanyu Yi, Zike Wu, Na Zhao, Long Chen, Hanwang Zhang
European Conference on Computer Vision (ECCV) 2024
In the diffusion model, we proposed effective multi-view consistency designs that harmonize the inconsistent multi-view image guidance by integrating with 3D Gaussian Splatting (3DGS) characteristics, offering high-quality 3DGS editing.
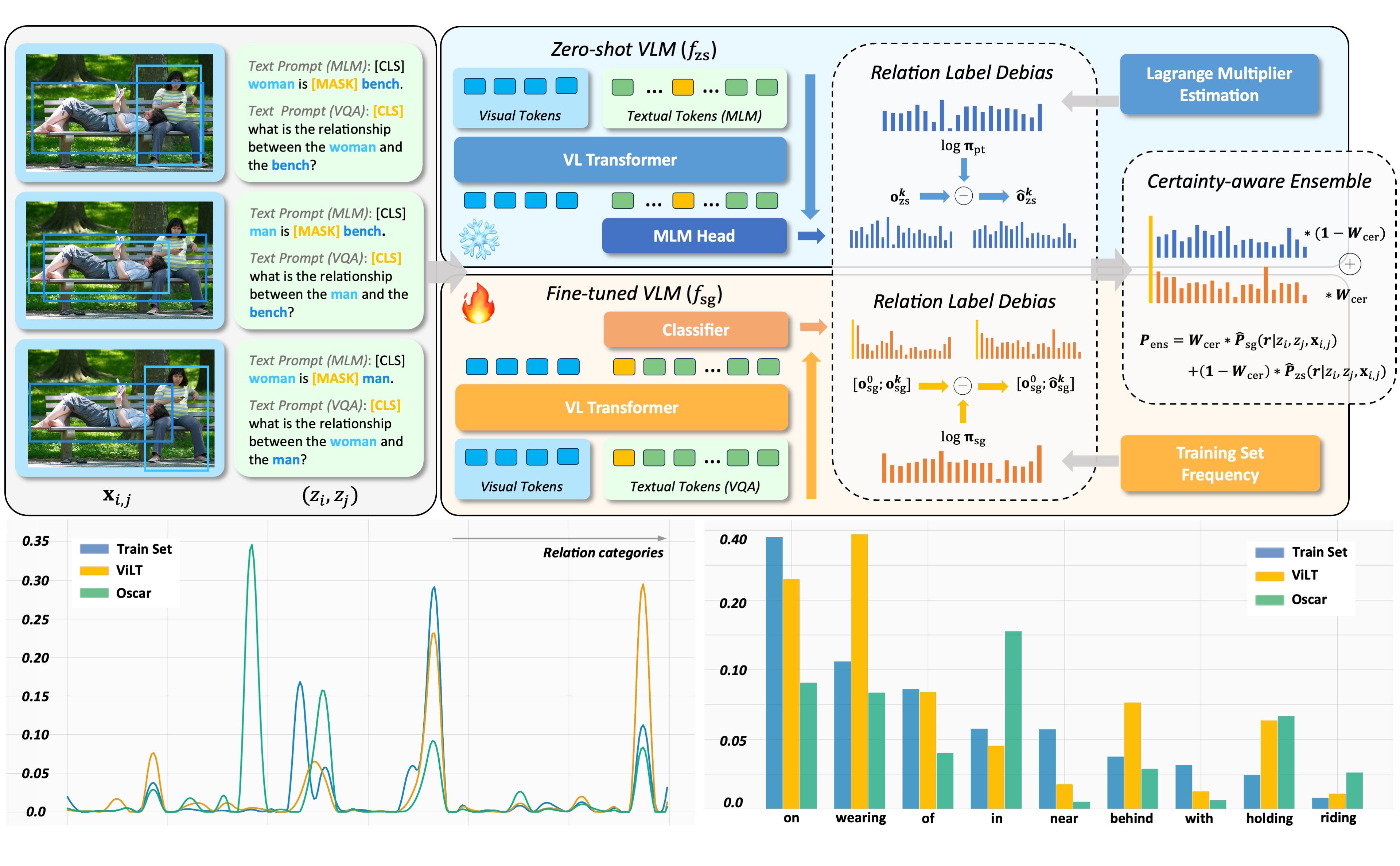
Predicate Debiasing in Vision-Language Models Integration for Scene Graph Generation
Yuxuan Wang, Xiaoyuan Liu
Empirical Methods in Natural Language Processing (EMNLP) 2024
We introduced a plug-and-play debiasing method for the zero-shot VLMs, dynamically ensembling them to address the underrepresentation issue in Scene Graph Generation (SGG) models.
Predicate Debiasing in Vision-Language Models Integration for Scene Graph Generation
Yuxuan Wang, Xiaoyuan Liu
Empirical Methods in Natural Language Processing (EMNLP) 2024
We introduced a plug-and-play debiasing method for the zero-shot VLMs, dynamically ensembling them to address the underrepresentation issue in Scene Graph Generation (SGG) models.
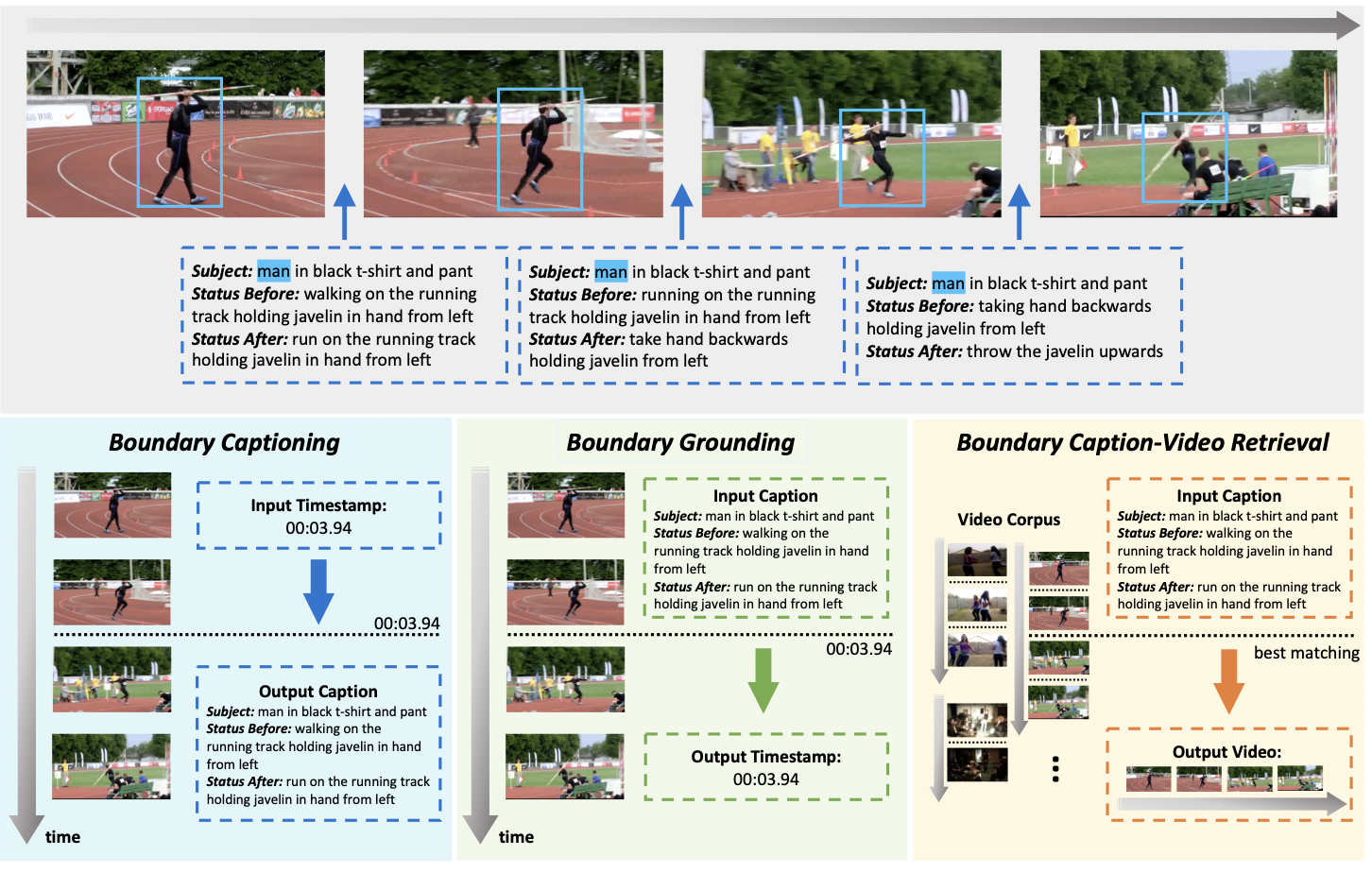
GEB+: A Benchmark for Generic Event Boundary Captioning, Grounding and Retrieval
Yuxuan Wang, Difei Gao, Licheng Yu, Stan Weixian Lei, Matt Feiszli, Mike Zheng Shou
European Conference on Computer Vision (ECCV) 2022
We introduced three tasks of video boundary understanding on our new dataset called Kinetics-GEB+ (Generic Event Boundary Plus), consisting of over 170k boundaries associated with captions in 12K videos. Besides, we designed a new Temporal-based Pairwise Difference (TPD) Modeling method for visual difference representation and achieved significant performance improvements.
GEB+: A Benchmark for Generic Event Boundary Captioning, Grounding and Retrieval
Yuxuan Wang, Difei Gao, Licheng Yu, Stan Weixian Lei, Matt Feiszli, Mike Zheng Shou
European Conference on Computer Vision (ECCV) 2022
We introduced three tasks of video boundary understanding on our new dataset called Kinetics-GEB+ (Generic Event Boundary Plus), consisting of over 170k boundaries associated with captions in 12K videos. Besides, we designed a new Temporal-based Pairwise Difference (TPD) Modeling method for visual difference representation and achieved significant performance improvements.

PBR3DGen: A VLM-guided Mesh Generation with High-quality PBR Texture
Xiaokang Wei, Bowen Zhang, Xianghui Yang, Yuxuan Wang, Chunchao Guo, Xi Zhao, Yan Luximon
AAAI Conference on Artifical Intelligence (AAAI), 2026
In this work, we present PBR3DGen, a two-stage mesh generation method with high-quality PBR materials that integrates the novel multi-view PBR material estimation model and a 3D PBR mesh reconstruction model.
PBR3DGen: A VLM-guided Mesh Generation with High-quality PBR Texture
Xiaokang Wei, Bowen Zhang, Xianghui Yang, Yuxuan Wang, Chunchao Guo, Xi Zhao, Yan Luximon
AAAI Conference on Artifical Intelligence (AAAI), 2026
In this work, we present PBR3DGen, a two-stage mesh generation method with high-quality PBR materials that integrates the novel multi-view PBR material estimation model and a 3D PBR mesh reconstruction model.
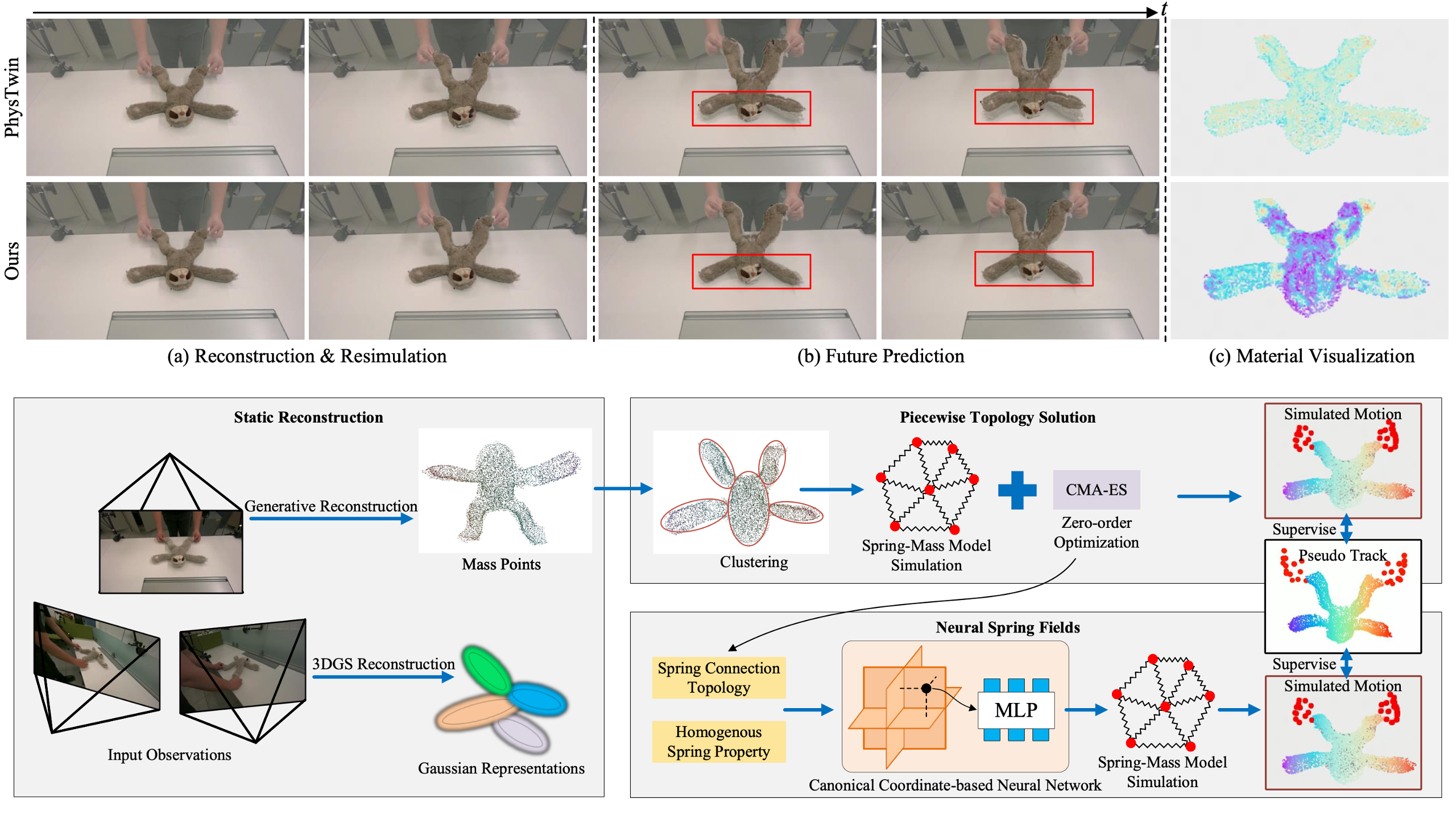
NeuSpring: Neural Spring Fields for Reconstruction and Simulation of Deformable Objects from Videos
Qingshan Xu, Jiao Liu, Shangshu Yu, Yuxuan Wang, Yuan Zhou, Junbao Zhou, Jiequan Cui, Yew-Soon Ong, Hanwang Zhang
AAAI Conference on Artifical Intelligence (AAAI), 2026
We present NeuSpring, a neural spring field for the reconstruction and simulation of deformable objects from videos, achieving superior reconstruction and simulation performance for current state modeling and future prediction.
NeuSpring: Neural Spring Fields for Reconstruction and Simulation of Deformable Objects from Videos
Qingshan Xu, Jiao Liu, Shangshu Yu, Yuxuan Wang, Yuan Zhou, Junbao Zhou, Jiequan Cui, Yew-Soon Ong, Hanwang Zhang
AAAI Conference on Artifical Intelligence (AAAI), 2026
We present NeuSpring, a neural spring field for the reconstruction and simulation of deformable objects from videos, achieving superior reconstruction and simulation performance for current state modeling and future prediction.
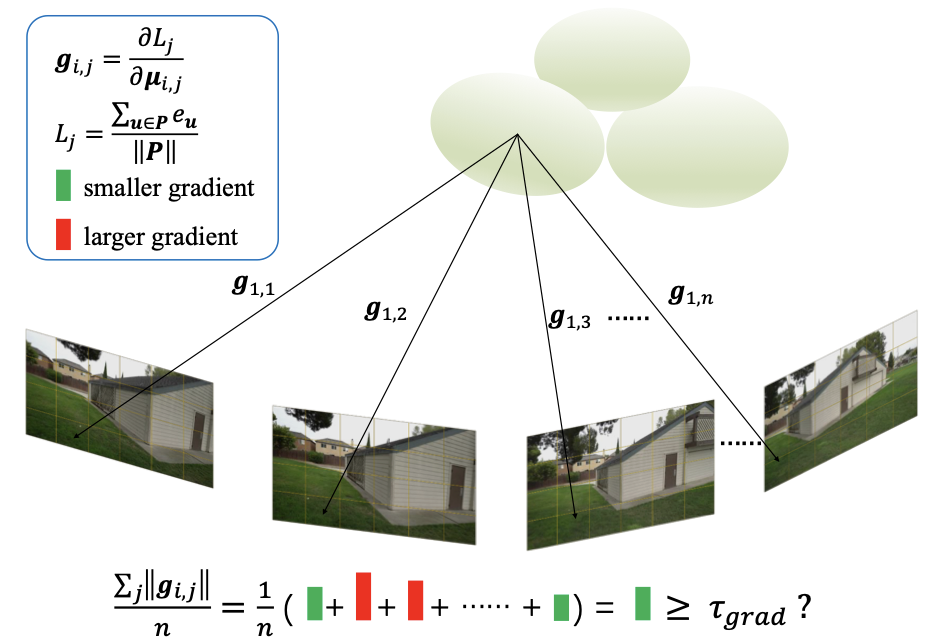
Pushing Rendering Boundaries: Hard Gaussian Splatting
Qingshan Xu, Jiequan Cui, Xuanyu Yi, Yuxuan Wang, Yuan Zhou, Yew-Soon Ong, Hanwang Zhang
AAAI Conference on Artifical Intelligence (AAAI), 2026
We propose Hard Gaussian Splatting, dubbed HGS, which considers multi-view significant positional gradients and rendering errors to grow hard Gaussians that fill the gaps of classical Gaussian Splatting on 3D scenes, thus achieving superior NVS results.
Pushing Rendering Boundaries: Hard Gaussian Splatting
Qingshan Xu, Jiequan Cui, Xuanyu Yi, Yuxuan Wang, Yuan Zhou, Yew-Soon Ong, Hanwang Zhang
AAAI Conference on Artifical Intelligence (AAAI), 2026
We propose Hard Gaussian Splatting, dubbed HGS, which considers multi-view significant positional gradients and rendering errors to grow hard Gaussians that fill the gaps of classical Gaussian Splatting on 3D scenes, thus achieving superior NVS results.
DragNeXt: Rethinking Drag-Based Image Editing
Yuan Zhou, Junbao Zhou, Qingshan Xu, Kesen Zhao, Yuxuan Wang, Hao Fei, Richang Hong, Hanwang Zhang
AAAI Conference on Artifical Intelligence (AAAI), 2026
We propose a simple-yet-effective editing framework, dubbed DragNeXt, redefining Drag-Based Image Editing (DBIE) as deformation, rotation, and translation of user-specified handle regions.
DragNeXt: Rethinking Drag-Based Image Editing
Yuan Zhou, Junbao Zhou, Qingshan Xu, Kesen Zhao, Yuxuan Wang, Hao Fei, Richang Hong, Hanwang Zhang
AAAI Conference on Artifical Intelligence (AAAI), 2026
We propose a simple-yet-effective editing framework, dubbed DragNeXt, redefining Drag-Based Image Editing (DBIE) as deformation, rotation, and translation of user-specified handle regions.
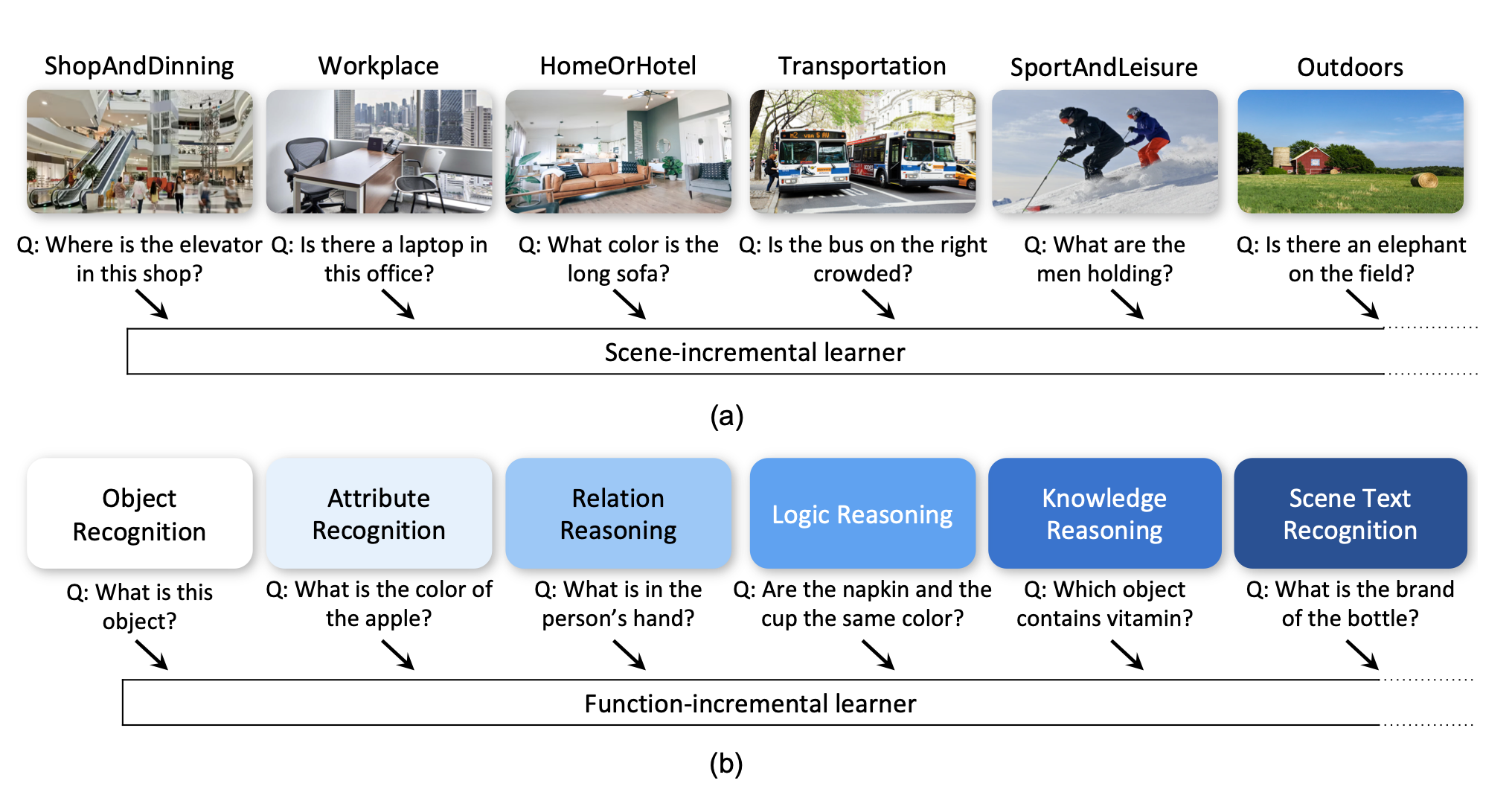
Symbolic Replay: Scene Graph as Prompt for Continual Learning on VQA Task
Stan Weixian Lei*, Difei Gao*, Jay Zhangjie Wu, Yuxuan Wang, Wei Liu, Mengmi Zhang, Mike Zheng Shou ( * co-first authors)
AAAI Conference on Artifical Intelligence (AAAI), 2023
We introduced Scene Graph as Prompt (SGP) for symbolic replay, a real-data-free replay-based method for Continual Learning VQA, which overcomes the limitations of replay-based methods by leveraging the scene graph as an alternative to images for replay.
Symbolic Replay: Scene Graph as Prompt for Continual Learning on VQA Task
Stan Weixian Lei*, Difei Gao*, Jay Zhangjie Wu, Yuxuan Wang, Wei Liu, Mengmi Zhang, Mike Zheng Shou ( * co-first authors)
AAAI Conference on Artifical Intelligence (AAAI), 2023
We introduced Scene Graph as Prompt (SGP) for symbolic replay, a real-data-free replay-based method for Continual Learning VQA, which overcomes the limitations of replay-based methods by leveraging the scene graph as an alternative to images for replay.

AssistSR: Task-oriented Video Segment Retrieval for Personal AI Assistant
Stan Weixian Lei, Difei Gao, Yuxuan Wang, Dongxing Mao, Zihan Liang, Lingmin Ran, Mike Zheng Shou
Findings of Empirical Methods in Natural Language Processing (EMNLP) 2022
We introduce a new dataset and a new task called Affordance-centric Question-driven Video Segment Retrieval (AQVSR), aiming at retrieving affordance-centric instructional video segments given users’ questions. To address the task, we developed a straightforward model called Dual Multimodal Encoders (DME).
AssistSR: Task-oriented Video Segment Retrieval for Personal AI Assistant
Stan Weixian Lei, Difei Gao, Yuxuan Wang, Dongxing Mao, Zihan Liang, Lingmin Ran, Mike Zheng Shou
Findings of Empirical Methods in Natural Language Processing (EMNLP) 2022
We introduce a new dataset and a new task called Affordance-centric Question-driven Video Segment Retrieval (AQVSR), aiming at retrieving affordance-centric instructional video segments given users’ questions. To address the task, we developed a straightforward model called Dual Multimodal Encoders (DME).
Others about Me
I love music and enjoy playing the piano and guitar. I used to sing as a tenor in BUAA Chorus and enjoyed sharing some covers on Netease and QQ Music. Some of my best friends are incredible music players and singers, and I’m so thankful for all the happiness they’ve brought me through music.
A special thanks to my girlfriend, Sijing, for always being by my side with her support and love.